Imitrob dataset version 2.0
IROS24
In proceedings IEEE/RSJ International Conference on Intelligent Robots and Systems, 2024, Detroit
We present Imitrob, a real-world benchmark dataset with 6D annotations designed for imitation learning, featuring human operators holding tools and demonstrating various tasks. The dataset spans nine hand-held tools (4 glue guns, a heat gun, a powerdrill, a soldering iron, a grout float and a roller), four human subjects, left and right hand scenarios, two camera viewpoints and various number of tasks for each tool. The image sequences are completely annotated with 6D pose of the tool, coordinates of the end effector etc. The spatial information about the tools was collected from a HTC Vive controller attached on top of them.
The dataset consists of two main subsets: Test, showing the tools "in action" in industrial-like environments (along with ground truth annotations and evaluation metrics), and Train, showing the tools being manipulated in front of a green background (supplied with augmentation methods). Train contains 39 326 images in total and can be used for algorithm training, Test (61 660 images) is suitable for evaluation.
The main idea behind Imitrob is to simulate real-world industrial usecases and their usual demands on the 6D object pose estimation algorithms: high precision of the pose estimation under heavy object occlusions, absence of the object 3D model (which is difficult to provide), handling of noisy/cluttered environments etc. It should thus help the users estimate the plausibility of a selected pose estimation algorithm for their own project.
Citation
See the link below for a quick hands-on overview of the dataset content. The whole dataset can be downloaded as a .zip. We cover all the details for each subset in the following sections and also in the attached README files.
Browse individual folders:
Imitrob structureDownload as .zip:
Imitrob Test (51 GB), Imitrob Train (84 GB), Imitrob Train Light (55 GB)Link to supplementary code:
Imitrob GithubSupplementary material
Download .pdf Imitrob Supplementary material Supplementary material contains: Calibration details, Definition of evaluation metrics, Details about the object segmentation methods, DOPE estimator parameters, Impact of image resolution and batch size, Additional results for Generalization)Dataset meta-data file: Download .json meta-data file
Dataset datasheet: Download .pdf Imitrob datasheet file
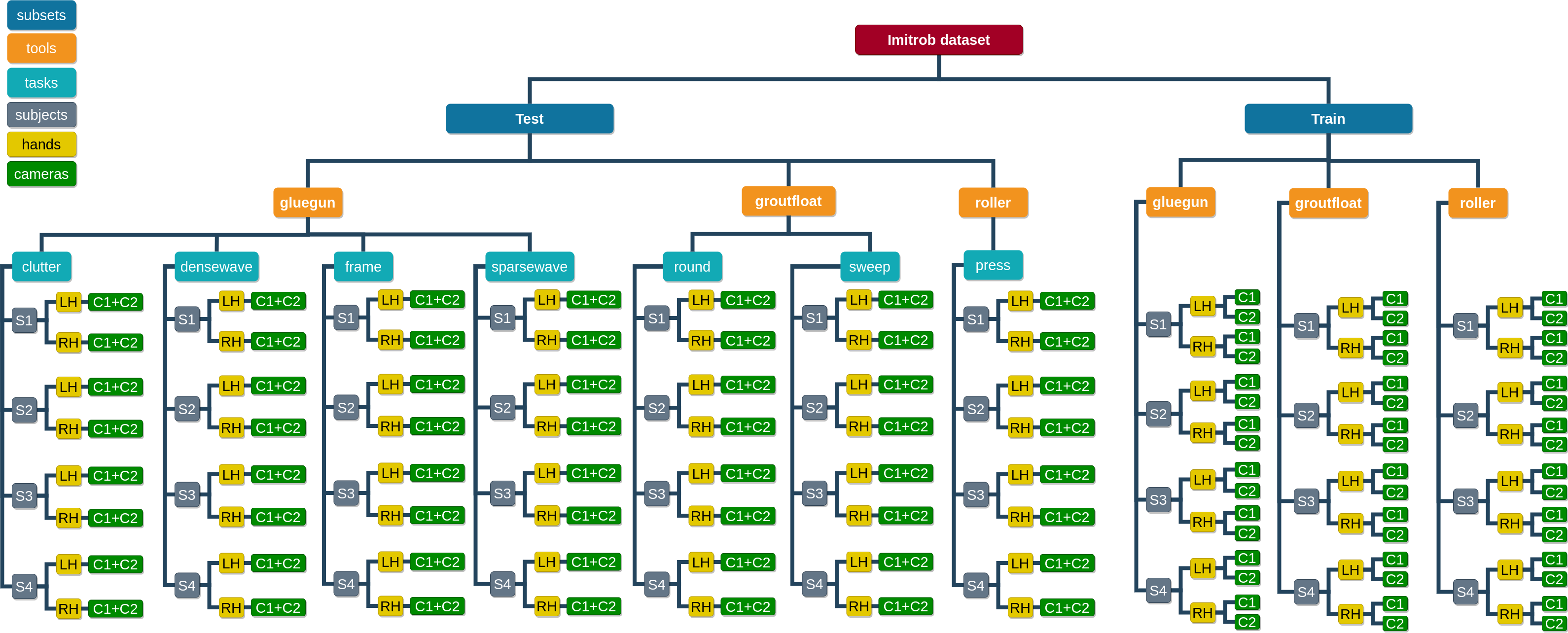
In the following section, we describe the two subsets in greater detail.
Test subset
The Test subset contains 56 video sequences depicting a human operator using one of the tools to perform a certain task. For each of the sequences, we provide the following processed folders and files:- 6DOF/ - contains .json files with 6D pose data of the recorded tool for each video frame
- BBox/ - contains the bounding box coordinates (again in .json)
- Depth/ - contains the depth images of the whole scene
- Image/ - contains RGB image of each frame
- parameters.json - contains coordinates of the 8 vertices of the bounding box for the tool with respect to the HTC Vive Tracker ("BB_in_tracker" ) and intrinsic camera matrices for Camera 1 ("K_C1" ) and 2 ("K_C2" ).
Although the Test subset was recorded from two camera viewpoints same as the Train subset, both viewpoint images are placed together in the Image and Depth folders (marked as C1*.jpg and C2*.jpg), whereas they are in two separate folders in the Train subset. This is because both cameras are synchronised in the Test subset, therefore the 6DOF and BBox folders are valid for both of them.
Below is a video showing a sequence of all tasks for all tools and all four subjects (columns), captured by the two cameras (rows). The bounding boxes are visualized in the two bottom rows.
Train subset
The Train subset consists of 48 video sequences altogether, capturing each one of the three tools being manipulated randomly against a green background. There is a HTC Vive tracker attached on top of the tool to capture the 6D pose of the object. The data provided for this subset are the same as in the Test subset, plus two additional Mask and Mask_thresholding folders. The structure is thus following (the descriptions are the same as for the Test subset section):- 6DOF/
- BBox/
- Depth/
- Image/
- Mask/
- Mask_thresholding/
- parameters.json
Supplementary code
We also provide supplementary code with various augmentation methods to increase the algorithm performance. You can find the code on our Imitrob Github. The code also includes scripts that demonstrate the training process on a state-of-the-art algorithm DOPE (Tremblay et al., 2018). You can also download the pre-trained DOPE weights.
Licensing
The newly provided datasets and benchmarks are copyrighted by us and published under the CC BY-NC-SA 4.0 license.To use the code or the dataset, please, give us an attribute, using the citation below.
Linked paper:
Imitrob: Imitation Learning Dataset for Training and Evaluating 6D Object Pose Estimators
Erratum
The main changes to the dataset and code are listed here. If you found any issue with the dataset, please let us know so we can fix it(karla.stepanova@cvut.cz):Usage of the dataset
Please, if you used/are willing to use our dataset, let us know so we can list you here. It will also make us happy and feel that our effort to prepare the dataset was useful. Any contributions to the dataset are also welcomed!Contact: karla.stepanova@cvut.cz.
The dataset has been used in the following works: