Abstract
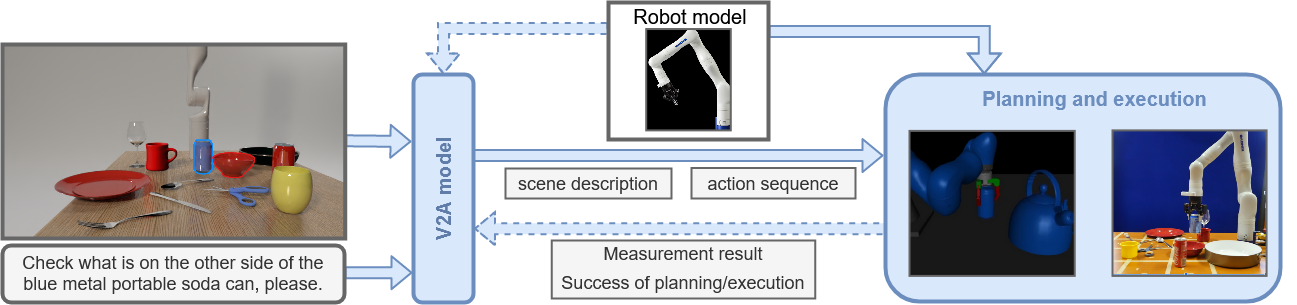
In this paper we present an integrated system that includes a reasoning from visual and natural language inputs, action and motion planning, executing tasks by a robotic arm, manipulating objects and discovering their properties. The vision to action module recognises the scene with objects and their attributes and analyses enquiries formulated in natural language. It performs multi-modal reasoning and generates a sequence of simple actions that can be executed by the embodied agent. The scene model and action sequence are sent to the planning and execution module that generates motion plan with collision avoidance, simulates the actions as well as executes them by the embodied agent. We extensively use simulated data to train various components of the system which make it more robust to changes in the real environment thus generalise better. We focus on the tabletop scene with objects that can be grasped by our embodied agent, which is 7DoF manipulator with a two-finger gripper. We evaluate the agent on 60 representative queries repeated 3 times (e.g., 'Check what is on the other side of the soda can') concerning different objects and tasks in the scene. We perform experiments in simulated and real environment and report the success rate for various components of the system. Our system achieves up to 80.6\% success rate on challenging scenes and queries. We also analyse and discuss the challenges that such intelligent embodied system faces.
